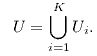
Изображение размера mx*my будем описывать тремя байтовыми матрицами R,G,B того же размера. Матрицы можно рассматривать как функции R(x,y), G(x,y), B(x,y) от целочисленных переменных 0 ≤x < mx, 0 ≤ y < my, принимающие целые значения от 0 до 255. Указанное множество целых точек на плоскости будем обозначать Umx,my, или просто U.
В случае необходимости, с помощью некоторых
интерполяционных формул, эти функции можно продолжить на всю плоскость
и рассматривать их уже как отображения R2 → R3.
Чаще всего применяют билинейную или бикубическую интерполяцию,
однако в каждом конкретном случае выбор интерполяционной формулы
будем оговаривать отдельно.
Норма в цветовом пространстве
Таким образом, цвет пиксела является точкой в трехмерном цветовом (RGB) пространстве. Для определения расстояния между цветовыми точками введем в RGB-пространстве метрику с помощью евклидовой нормы. Простейший способ её определения — как суммы квадратов:
Однако, более правильным, по всей видимости, следует признать евклидову норму в YUV-пространстве,
| y = 0.299*r + 0.587*g + 0.114*b |
| u = -0.16874*r -0.33126*g+0.50000*b |
| v = 0.50000*r -0.41869*g-0.08131*b |
то есть как квадратичную форму с матрицей
| 0.3678741876 | 0.0220648124 | -0.0909390000 |
| 0.0220648124 | 0.6296035037 | -0.0646683161 |
| -0.0909390000 | -0.0646683161 | 0.2696073161 |
С другой стороны, вполне разумным, представляется определить норму как
Отметим, что выбор той или иной нормы в цветовом пространстве не окажет существенного влияния на изучаемые алгоритмы. Просто зафиксируем некоторый способ нахождения расстояния между точками в цветовом пространстве.
Кроме того вводим дополнительный, служебный сегмент U0, состоящий из «несегментированных» точек. В начале алгоритма сегментации все точки относим к сегменту U0, затем, в процессе сегментации каждая точка будет отнесена к одному из Ui, i ≥ 1.
При определении сегментации на подмножества Ui не было наложено никаких ограничений. На самом деле на них обычно накладываются определённые условия, например:
Определение. Сегментацию будем называть нормализованной, если:
От любой сегментации можно ествественым способом перейти к
нормализованной. Этот переход будем называть нормализацией.
Численная оценка качества сегментации
Понятие качества сегментации в общем виде формализовать трудно. Тем не менее, попробуем предложить некоторый вариант численной оценки. Это позволит сравнивать между собой различные программы и выявлять лучшие.
Рассмотрим пару полноцветных (TrueColor) изображений, не обязательно одинакового размера.
Segm_test2.pdf – более подробное описание.
Segm_by_squares.exe – програма (Windows) для тривиальной сегментации (на квадраты).
segm_show.exe – програма (Windows) для просмотра сегментации.
С вычислительной точки зрения сегментацией изображения размера mx*my
будем называть матрицу того же размера из натуральных чисел.
Каждое число обозначает номер сегмента (>0), к которому принадлежит точка.
Такие матрицы сохраняются в текстовом файле вида
mx my комментарий s00 s10 … s01 s11 … …
например, при сегментации файла размером 4*3:
4 3 ; в первой строке файла заданы размеры матрицы по x (4) и по y (3) 1 2 1 1 2 2 1 1 2 2 2 3
где цифры в теле матрицы означают номер сегмента (>0), к которому относится каждая точка.
Номера сегментов не обязаны идти подряд. Никакое упорядочение сегментов также не требуется.
Во многих алгоритмах требуется обойти все точки изображения в некотором (псевдо)случайном порядке. Пронумеруем точки изображения, точнее говоря, области U=Umx,my целыми числами от 0 до mx*my-1. Таким образом, задача сводится к псевдослучайному обходу всех точек из множества {0, ..., N-1}, где N=mx*my.
Наиболее прост линейный метод. Выбираем натуральное число k, взаимно простое с N и начиная с произвольного x0 находим следующее число по формуле:
Однако при обработке изображений такой метод дает не слишком хорошие результаты. Поэтому построим более сложный алгоритм, заменим в предыдущей формуле сложение на умножение. Воспользуемся следующим утверждением:
Предложение. Пусть p — простое число и a — первообразный корень по модулю p. Тогда среди чисел
Обходить в этом случае будем числа от 1 до N. Выберем простое число p большее N. Начиная с произвольного x0 находим следующее число по формуле:
Если очередное число xn+1 оказалось больше N, то его пропускаем и делаем следующую итерацию. Процесс повторяем до тех пор, пока вновь не получим x0.
Пример. Пусть N=10. Выберем p=17, a=3. Пусть x0=7. Тогда последовательность вычислений будет такова:
Таким образом, мы получили обход натуральных чисел от 1 до N=10 в псевдослучайном порядке:
Простое число p должно быть больше N, но не слишком значительно, так как количество «холостых» шагов равно p-N. Подходящие простые числа p и первообразные корни a можно приготовить заранее для всех возможных N, например, следующие:
| p | a | p | a | |
|---|---|---|---|---|
| 17 | 3 | 8388617 | 3 | |
| 37 | 2 | 16777259 | 2 | |
| 67 | 2 | 33554467 | 2 | |
| 131 | 2 | 67108879 | 3 | |
| 257 | 3 | 134217757 | 5 | |
| 521 | 3 | 268435459 | 2 | |
| 1031 | 14 | 536870923 | 3 | |
| 2053 | 2 | 1073741827 | 2 | |
| 4099 | 2 | 2147483659 | 2 | |
| 8209 | 7 | 4294967311 | 3 | |
| 16411 | 3 | 8589934609 | 19 | |
| 32771 | 2 | 17179869209 | 3 | |
| 65537 | 3 | 34359738421 | 2 | |
| 131101 | 17 | 68719476767 | 5 | |
| 262147 | 2 | 137438953481 | 3 | |
| 524309 | 2 | 274877906951 | 7 | |
| 1048583 | 5 | 549755813911 | 3 | |
| 2097169 | 47 | 1099511627791 | 3 | |
| 4194319 | 3 | 2199023255579 | 2 |
Результаты работы многих сравнительно простых алгоритмов сегментации
выглядят неудовлетворительно. Однако их можно
существенно улучшить, причем методы улучшения можно применять
практически ко всем алгоритмам.
Клеточный автомат
Идея клеточного автомата очень простая. Если точка принадлежит некоторому сегменту a, но большинство соседних принадлежат другому сегменту b ≠ a, то относим и эту точку к сегменту b.
У каждой внутренней точки (x,y) области U есть четыре соседних точки: вверх-вниз и вправо-влево. Помимо этого у точки можно рассмотреть и восемь соседних. Поэтому «большинство» можно искать как среди четырех, так и среди восьми соседей.
Более правильным следует признать «взвешенный» подход, когда четыре соседние точки (верх-низ-право-лево) рассматриваются с одним весом, а остальные четыре соседа с другим, меньшим весом. Учитывая, что расстояние до диагонального соседа в sqrt(2) раз больше, чем до ближайшего, то и вес его надо брать во столько же раз меньше. Чтобы не переходить к дробным числам, будет лучше взять вес четырех ближайших соседей равным 3, а четырех диагональных 2. Таким образом, сумма весов соседних восьми точек равна 20.

Поэтому правило клеточного автомата можно сформулировать так:
Если точка принадлежит некоторому сегменту a, но «взвешенное» большинство соседних принадлежат другому сегменту b ≠ a, то относим и эту точку к сегменту b.
Это правило надо применить одновременно ко всем точкам исходной матрицы. Фактически это означает, что надо строить новую матрицу того же размера с новой сегментацией и повторять этот процесс до тех пор, пока матрица не стабилизируется.
Практически того же самого результата можно добиться и с одной-единственной матрицей. Для этого на каждом шаге надо обойти все точки матрицы (в псевдослучайном порядке) и для каждой точки выполнить указанную выше операцию.
У точек на краю области U количество соседей меньше. Но для более однородного выполнения алгоритма можно распространить исходную сегментацию и на целые точки за пределом области U, например, считать, что точка (-1,y) относится к тому же сегменту, что и точка (0,y).
Сглаживание с помощью клеточного автомата — это сравнительно
простой, но весьма надежный и эффективный инструмент. Его стоит
использовать после почти любого метода сегментации.
Морфологическое сглаживание
Определение. Будем называть точку из сегмента Ui граничной, если одна из восьми соседних точек принадлежит другому сегменту. Множество всех граничных точек будем называть внутренней границей сегмента.
Определение. Внешней границей сегмента Ui будем называть множество точек не принадлежащих сегменту таких, у которых одна из восьми соседних принадлежит этому сегменту.
Определение.
а) Замыканием сегмента будем называть присоединение к нему его
внешней границы.
б) Эрозией сегмента будем называть перевод его внутренней границы в
нулевой сегмент, то есть в несегментированные точки.
Будем предполагать, что сегментация нормализована, то есть размеры сегментов убывают с ростом номера.
Определение. Морфологическим сглаживанием сегментации будем называть последовательное замыкание всех сегментов начиная с 1-го и до последнего.
Определение. Сегмент называется связным, если из любой его точки можно добраться до любой другой по точкам сегмента, каждый раз переходя к одной из восьми соседних точек.
Вполне естественным требованием является связность каждого сегмента в сегментации.
Каждая область может быть разбита в непересекающееся объединение связных компонент. Поэтому от произвольной сегменатции можем перейти к сегментации со связными сегментами. Следует учитывать, что при этом количество сегментов может значительно (и непредсказуемо) вырасти. После перехода к связным сегментам придется проводить повторную нормализацию.
Вряд ли целесообразно иметь сегменты размеров в 10-20 точек. От них лучше избавиться. Для этого сначала переведем точки таких сегментов в нулевой сегмент (то есть есть в несегментированные точки). Затем последовательно присоединяем точки нулевого сегмента к соседним. Для этого на каждом шаге рассматриваем точки внутренней границы нулевого сегмента и каждую из них присоединяем к тому сегменту, чья взвешенная сумма среди восьми соседей больше.
Предложенный алгоритм присоединения несегментированных точек к сегментам является простейшим, но не самым лучшим. Более правильным будет на каждом шаге выбрать пару 4-соседних точек (u,v) таких, что u лежит в нулевом сегменте, v — в ненулевом и цветовое расстояние между ними минимально среди всех таких пар. Теперь присоединяем точку u к сегменту точки v. Фактически, это есть алгоритм "сегментации через кристаллизацию", рассмотренный ниже.
Иногда связный сегмент оказывается состоящим из нескольких массивных частей соединенных узкими перемычками. В таком сегменте каждую массивную часть стоит выделить в отдельный сегмент. Для этого с каждым сегментом выполняем следующие действия.
Таким образом, единственным параметром оптимизации является минимальный размер сегмента N0.
Для эффективной работы с сегментами требуется знать, какие сегменты являются соседними, какова величина общей границы, насколько близка два сегмента в разных смыслах. Для формализации этого введем понятия топологии сегментов. Пусть
Определение. Обозначим через Tij количество граничных пар для пары сегментов (Ui,Uj). Будем считать, что Tii равно количеству всех граничных пар сегмента Ui, то есть
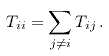
Определение. Обозначим через Sij среднее цветовое расстояние между цветами граничных пар для пары сегментов (Ui,Uj). Будем считать, что Sij=0, если нет общих пар или i=j.
Зная топологию сегментов можно эффективно сокращать из количество, то есть присоединять один сегмент к другому. А именно, для присоединения сегмента Uj к большему сегменту Ui (то есть i>j), потребуем, чтобы
Этот алгоритм будем называть топологической минимизацией количества сегментов.
Сегментация через триангуляцию
Рассмотрим следующий алгоритм сегментации изображения.
Шаг 1. Построение точек. В начале ставим 4 угловые точки. Затем добавляем по одной, ту - где длина градиента наибольшая, но не слишком близко к уже поставленным точкам, пока не получим нужное количество точек (а значит, и треугольников).
Шаг 2. Триангуляция Делоне построенной сети.
Оптимизация в этом случае, фактически не требуется. Однако, можно задать избыточное количество точек, получить избыточное количество сегментов и затем провести топологическую минимизацию сегментов до требуемого количества.
Segm_tri.exe – програма (Windows) для сегментации через триангуляцию.
Формат данных описан выше.
Пример. Рассмотрим изображение lena.bmp размера 512*512. В результате выполнение команды
Segm_tri.exe lena.bmp lena.txt 100
получим файл lena.txt с триангуляцией на 100 треугольноков и, дополнительно, segm1.bmp
просто для иллюстрации результата:
 |  |
Сегментация через кристаллизацию
Рассмотрим следующий алгоритм сегментации изображения. Пусть дано некоторое ожидаемое количество сегментов N.
Шаг 1. Выбираем удвоенное количество точек (2N), — центров будущих сегментов. Точки выбираем в тех местах, где усредненное значение длины градиента как можно меньше, причем точки не должны быть близко друг к другу.
Шаг 2. Наращиваем все сегменты из их центров. Каждый раз присоединяем к сегменту соседние точки, которые отличаются оп цвету наименьшим образом. В результате получаем сегментацию на удвоенное количество сегментов.
Шаг 3. Оптимизация.
Шаг 4. Топологическая минимизация количества сегментов до тех пор, пока не получим заданное их количество.
Segm_cry.exe – програма (Windows) для сегментации через кристаллизацию.
segm_brd.exe – програма (Windows) для сегментации по границам.
Замечание. Представленные прогаммы написаны исключительно в исследоваетельских целях, не оптимизированы ни по времени, ни по памяти. Для практического применения желательно брать более эффективные программы.
Один из основных методов нахождения границ на изображении — «Canny edge detector».
Математическая суть его состоит в том, что точка называется граничной, если в ней достигается максимум модуля вектора градиента функции яркости в направлении роста функции, то есть в направлении самого вектора градиента. Переведем это определение на математическую основу.
Опишем алгоритм для одноцветного изображения, в реальности обычно берут функцию яркости:
Таком образом, пусть f(x,y) – функция яркости изображения, её градиент - это вектор с координатами
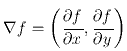 .
.
Рассмотрим квадрат длины градиента
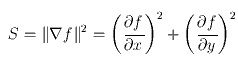 .
.
Точку назовем граничной, если производная от S по направлению градиента функции f равна 0:
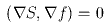 .
.
Так как градиент функции S равен
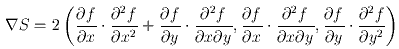 .
.
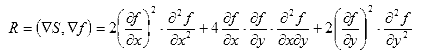 .
.
Если функция f(x,y) дважды непрерывно дифференцируема, то уравнения R(x,y)=0 задает на плоскости непрерывную кривую, овалы которой можно использовать в качестве основы для сегментации изображения.
В случае табличного задания функции f(x,y), мы должны построить дважды непрерывно дифференцируемую интерполяционную функцию. Такую интерполяционную формулу построить нетрудно, однако результат оказывается не слишком удовлетворительным. Например, для изображения, состоящего из одной-единственной белой точки на черном фоне, границы, построенные таким образом имеют вид:
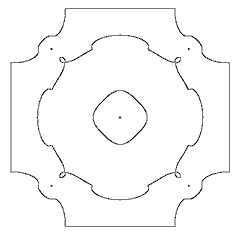 .
.
Для реальных же изображений, количество получаемых овалов оказывается чересчур велико для практических применений.
Однако, вместо того, чтобы искать интерполяционный многочлен класса C2, можно построить отдельные непрерывные интерполяционные формулы для производных функции f(x,y) первого и второго порядка. Для этого определим приближенные значения частных производных в целочисленных точках (x,y) по простейшим формулам
2*∂f/∂x ≈ f(x+1,y)-f(x-1,y),
2*∂f/∂y ≈ f(x,y+1)-f(x,y-1),
∂f2/∂x2 ≈ f(x+1,y)-2*f(x,y)+f(x-1,y),
4*∂f2/∂x ∂y ≈ f(x+1,y+1)-f(x+1,y-1)-f(x-1,y+1)+f(x-1,y-1),
∂f2/∂y2 ≈ f(x,y+1)-2*f(x,y)+f(x,y-1),
Предложенный способ построения граничных линий на изображении гораздо более естественен и устойчив. Например, в приведенном выше примере (белая точка на черном фоне) линия границы будет выглядеть так
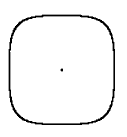 .
.
Для примера рассмотрим небольшой кусок (размером 16*16) стандартного изображения «lena.bmp» («правый глаз»). Граница, найденная описанным выше способом в этом случае выглядит так:

Построенные таким методом «границы» разбивают плоскость на чересчур большое количество областей. Поэтому сгладим предварительно изображение с радиусом 2, получим следующие границы:

Таким образом, при практической реализации, предлагаемый подход следует дополнить еще двумя шагами:
Замечание. На каждом единичном квадрате функция R(x,y) является бикубической, то есть имеет степень 3 по x и по y. Коэффициенты этой функции в единичном квадрате зависят от значения функции f(x,y) в 16-ти соседних точках:
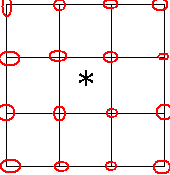
f00 f01 f02 f03 f10 f11 f12 f13 f20 f21 f22 f23 f30 f31 f32 f33однако получающиеся выражения совершенно необозримы. Например, коэффициент при x2y выглядит так (почти полностью):

Непрерывная сегментация, явные формулы
Пусть нам даны значения функции яркости в квадрате 3*3:
f00 f01 f02 f10 f11 f12 f20 f21 f22Тогда значение функции 8*R в центральной точке (1,1) равно:
8*R = 2(f21-f01)2(f21-2*f11+f01) + 2(f12-f10)2(f12-2*f11+f10) + (f21-f01)(f12-f10)(f22-f02-f20+f00)